什么是 AI 降噪及其核心工作逻辑?
AI 降噪是通过深度学习模型识别并分离有用信号(图像或音频)与随机噪声的技术。其逻辑是利用训练好的神经网络将噪声模式从原始数据中剥离,在尽可能还原纯净信号的同时,减少对细节的损耗。

到 2026 年 3 月,AI 降噪已从简单的“平滑处理”进化为“重建处理”。现在的 AI 不再只是抹除噪点,而是结合海量训练数据,在感知噪声的同时实时推测并填补缺失细节。这使得高 ISO 摄影作品或高背景噪声的录音具备了商业可用性。
图像与音频降噪虽然技术路径不同,但核心逻辑一致:通过对比“干净信号”和“含噪信号”样本建立映射模型。
图像与音频降噪的差异化应用
在图像领域,AI 主要对抗传感器在高温或低光环境下产生的热噪声和电噪声。传统降噪依赖模糊化覆盖,常导致照片出现“涂蜡感”,丢失皮肤纹理。而基于扩散模型的 AI 降噪器能区分“颗粒感”与“细节”,从而精准剔除干扰项。
在音频领域,AI 处理的是频谱分布。它通过分析频率,将空调风声等恒定底噪或敲击声等突发干扰与人声区分开。目前的 AI 音频降噪已能将家庭工作室的录音纯净度提升至接近录音室级别。
如何通过 AI 图像降噪还原高 ISO 画质?
掌握参数配置比选择工具更重要,因为影像创作者目前面临的核心矛盾是“真实感”与“纯净度”的平衡。过度处理会导致皮肤呈现塑料质感。
主流 AI 图像降噪工具分为集成在后期软件中的原生功能和独立专业软件。Lightroom 的 AI 降噪在 2024 年后提升明显,即便在 ISO 25600 的极端数值下也能有效保留轮廓,避免了大面积色块。DxO PureRAW 则在 Raw 文件转换阶段介入,结合光学矫正提供更自然的画质还原。
处理极高噪点照片的建议流程(以 Lightroom 为例)
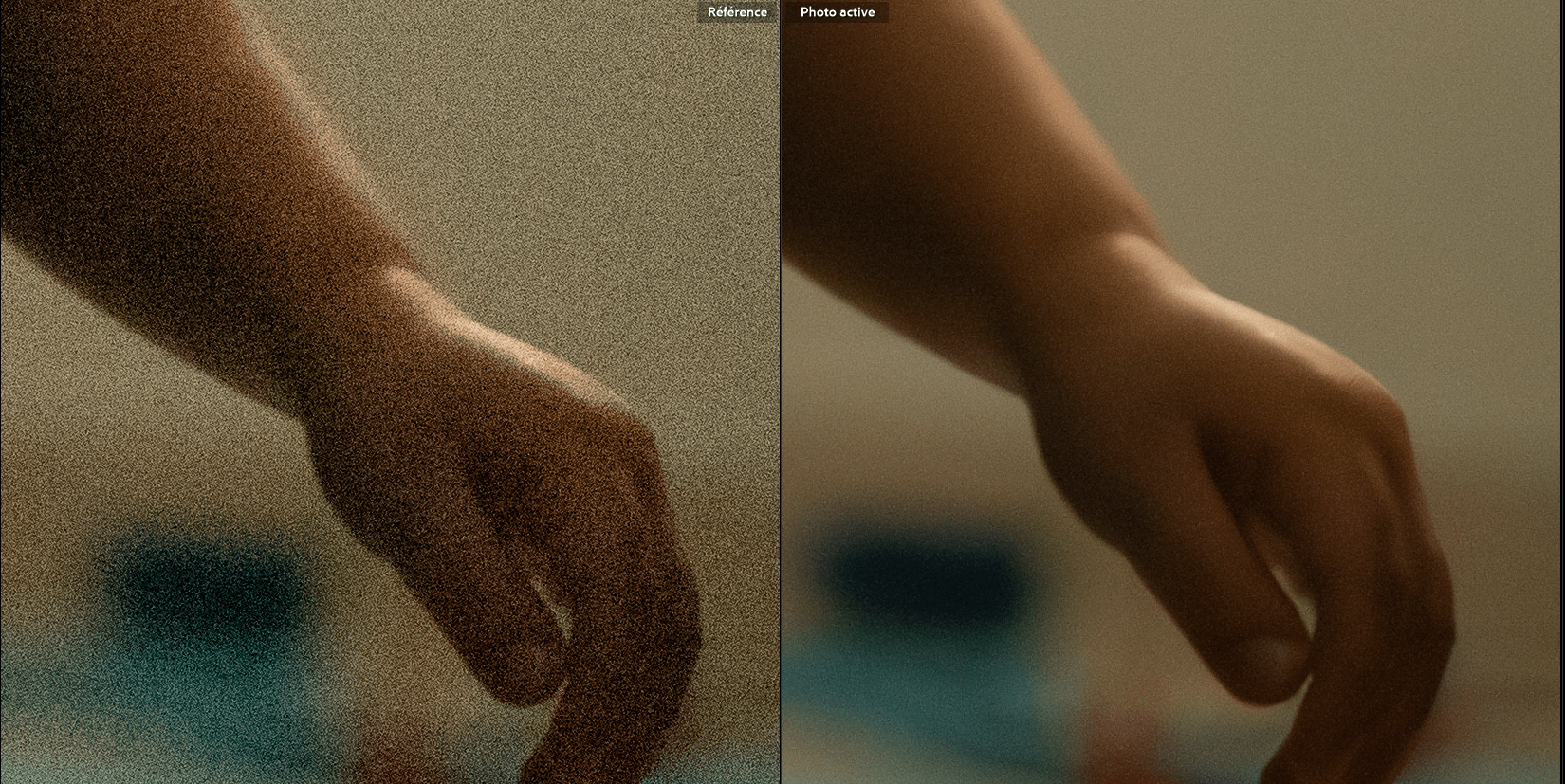
AI 音频降噪的实操指南与应用场景
音频 AI 降噪在播客和电影对白补录中应用广泛。UniConverter 等工具在处理速度上较快,且较少产生金属感(Artifacts)。
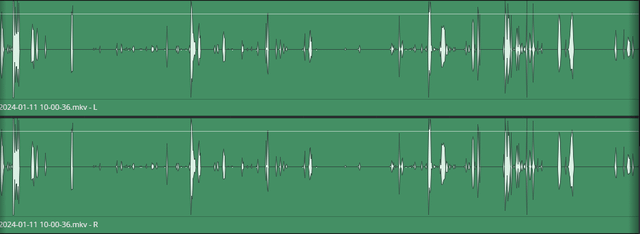
主流 AI 降噪产品对比分析

| 维度 | Lightroom | DxO PureRAW | 专业音频工具/插件 |
|---|---|---|---|
| 价格模式 | 订阅制,生态完整 | 倾向买断制,单价较高 | 多样化(免费/买断/订阅) |
| 核心优势 | 通用性强,出片快 | 极致的光学还原 | 高精度频谱控制 |
| 适用场景 | 社交媒体、日常摄影 | 商业大画幅打印 | 播客、电影对白补录 |
| 潜在风险 | 极端 ISO 可能产生色块 | 处理速度较慢 | 过度处理产生“空洞感” |
AI 降噪的局限性与最佳实践
AI 降噪并非万能药,在某些高精度场景中存在不可忽视的局限性。
首先是极低信噪比下的细节丢失。当噪声强度超过信号强度时,AI 实际上是在根据概率“猜测”原图,生成的细节并非真实存在。因此,在法律证据、医学影像等科学记录中,不可完全依赖 AI 降噪。
其次是时间成本与感官损失。处理大规模 Raw 文件集时时间成本显著;而在音频领域,过强的降噪会抽走环境中的自然空气感,使声音失去空间深度。
如何判断 AI 降噪是否“过度”?
最简单的判断方法是放大至 100% 观察细节边缘。如果皮肤纹理消失、物体边缘出现不自然的平滑光晕,或者音频中人声开始出现类似金属的电音感(Artifacts),即说明处理强度过高。建议将强度降低,保留 5%-10% 的自然噪声以维持真实感。
AI 降噪会改变原片的真实性吗?
是的。由于目前的 AI 降噪涉及“重建”而非简单的“剔除”,它会根据模型训练数据推测缺失细节。在追求艺术效果的商业摄影中这没有问题,但在需要绝对真实还原的科学记录或法庭证据中,建议使用传统线性降噪或保留原始含噪样本。
为什么 AI 降噪处理速度这么慢?
因为 AI 降噪需要对图像的每一个像素点进行复杂的神经网络计算。这种计算极度依赖 GPU(图形处理器)的算力。如果处理速度极慢,请检查是否开启了硬件加速,以及显存是否充足(建议 8GB 以上)。
实践建议:从“零噪声”转向“舒适噪声”
建议不要追求绝对的“零噪声”,而应追求“舒适的噪声”。保留少量的天然颗粒感能提升照片的电影感,适度的底噪能增强录音的真实性。
进阶练习:你可以尝试建立一个包含不同噪声程度的 Raw 或无损 WAV 测试库,在尝试新工具前进行盲测,对比细节保留率。尝试找一张 ISO 6400 以上的照片,在 30% 和 70% 的强度之间寻找细节消失的临界点,这将帮助你快速建立对工具的体感。